



목차

이번 글은 기본편과 심화편으로 나누어집니다.
- 기본편에서는 SQL 구문별 특징을 통해 ORM을 사용할 때 실수하기 쉬운 부분을 되짚어 봅니다.
- 심화편에서는 인덱스 튜닝, ORM 쿼리 응용하기 등 실전에 필요한 내용을 다룹니다.
Intro
ORM은 객체(Object)와 관계형 데이터베이스(Relational Database)를 연결해줍니다.
ORM을 이용하면 개발자가 SQL을 적지 않고도 프로그래밍 언어로 DML을 수행할 수 있습니다.
객체지향적인 코드를 통해 데이터를 다루기 때문에 코드 가독성이 높고, 이는 생산성을 높여줍니다.
또 lazy-loading이나 caching 같은 기능을 통해 불필요한 쿼리를 줄여주기도 합니다.
Django 역시 ORM을 지원합니다.
하지만 ORM에 장점만 있는 것은 아닙니다.
쿼리하는 데이터가 복잡할 수록 ORM이 불편한 경우가 있습니다.
ORM의 제약으로 인해 SQL의 모든 기능을 활용하지 못하기 때문입니다.
또 SQL을 제대로 이해하지 못하고 작성하는 ORM은 매우 비효율적인 쿼리를 만들어냅니다.
그럼에도 불구하고 ORM은 제대로 사용했을 경우 분명한 장점이 있습니다.
SQL의 특성을 이해하고 ORM을 제대로 사용할 수 있는 방법에 대해서 이야기 해보겠습니다.
Django ORM 기초
Queryset
기본적인 내용부터 시작합시다.
Django에서 하나의 모델 클래스는 하나의 데이터베이스 테이블에 해당합니다.
그리고 모델 클래스를 통해 생성한 하나의 인스턴스는 하나의 테이블 레코드에 해당합니다.
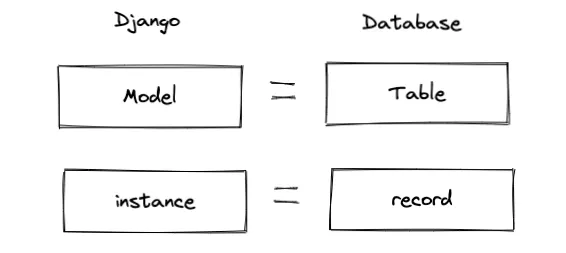
SQL은 기본적으로 테이블 단위로 쿼리하기 때문에 Django에서 역시 모델 클래스 단위로 쿼리합니다.
Django의 ORM 문법이 다음과 같이 클래스부터 시작하는 이유입니다.
>>> User
Python
복사
ORM에서 가장 처음 클래스부터 명시하는 것은 SQL의 FROM절을 적는 것과 같습니다.
데이터베이스에서 데이터를 읽어오기 위해서는 Manager를 통해 QuerySet을 만들어야 합니다.
User라는 모델 클래스의 objects라는 attribute가 Django ORM Manager에 해당합니다.
>>> User.objects
Python
복사
Django의 모든 모델 클래스는 기본적으로 objects라는 이름의 Manager를 가지고 있습니다.
Django의 ORM Manager는 모델과 데이터베이스 사이의 인터페이스입니다.
Manager가 있기 때문에 특정 조건의 쿼리를 재사용하는 등 추가적인 기능을 활용할 수 있습니다.
마지막으로 Manager에 쿼리하는 데이터에 대한 조건을 추가하면 쿼리셋이 완성됩니다.
다음 쿼리셋은 all() 메소드를 통해 User 테이블의 모든 레코드를 반환하게 됩니다.
>>> User.objects.all()
Python
복사
위의 쿼리셋은 아래의 SQL을 만들어냅니다.
SELECT
*
FROM
User
SQL
복사
설명을 위해 Django ORM 코드에 대응되는 SQL을 함께 적겠습니다.
그런데 이는 Django가 생성하는 실제 SQL과 약간 다를 수 있습니다.
Django가 생성하는 SQL은 테이블과 컬럼 이름을 명시적으로 적기 때문에 가독성이 좋지 않습니다.
따라서 읽기 쉬운 SQL로 가공했습니다. 쿼리 결과는 같은 동일한 SQL입니다.
filter() 메소드를 이용하면 SQL의 WHERE 절에 해당하는 쿼리를 생성할 수 있습니다.
>>> User.objects.filter(is_active=True)
Python
복사
SELECT * FROM User WHERE is_active = 1
SQL
복사
SQL & Execution Plan
ORM은 QuerySet이라는 객체를 통해 데이터를 반환합니다.
따라서 아래와 같이 반환값을 변수에 할당할 수 있습니다.
>>> queryset = User.objects.all()
Python
복사
QuerySet은 iterable한 객체입니다.
QuerySet은 하나의 SQL 쿼리에 대한 결과라고 생각해도 무방합니다.
QuerySet이 생성한 SQL은 다음과 같이 확인할 수 있습니다.
>>> str(queryset.query)
SELECT * FROM User
Python
복사
sqlparse를 이용하면 SQL을 보기 좋게 출력할 수 있습니다.
import sqlparse
query = str(queryset.query)
print(sqlparse.format(query, reindent=True))
Python
복사
SQL 실행 계획은 다음과 같이 확인 가능합니다.
>>> print(queryset.explain())
1 SIMPLE User None ALL None None None None 1 100.0 Using filesort
Python
복사
실행 계획은 쿼리의 성능 분석을 위해 반드시 확인해야 합니다.
기본 SQL
Django ORM을 익힐 때, 특정 메소드가 SQL 구문과 일대일로 대응한다고 생각하면 안 됩니다.
예를 들어, GROUP BY 구문에 완벽히 대응되는 메소드는 존재하지 않습니다.
메소드를 익히기 보다는 SQL을 이해하고, ORM이 동작하는 원리를 먼저 알아야 합니다.
문서를 보며 ORM 메소드 사용법을 아무리 봐도 원하는 데이터를 추출하지 못하는 이유입니다.
본격적으로 Django ORM을 사용할 때, 반드시 이해하고 있어야하는 내용을 알아봅시다.
집계 함수
aggregate()
SQL의 집계 함수를 이용하면 집합에 대한 연산을 쉽게 할 수 있습니다.
대표적인 집계 함수는 SUM, COUNT, AVG, MIN, MAX 등이 있습니다.
집계 함수의 특징은 여러 레코드로부터 하나의 결과값을 반환합니다.
Django ORM에서는 aggregate() 메소드를 통해 이를 지원합니다.
User 테이블의 전체 id 개수를 세고 싶다면, 다음과 같이 하면 됩니다.
>>> from django.db.models import Count
>>> User.objects.aggregate(Count('id'))
{"id__count": 3}
Python
복사
SELECT COUNT(id) AS id__count FROM User
SQL
복사
User 테이블의 전체 레코드가 하나의 결과로 집약된 것을 확인할 수 있습니다.
__count는 Django에 의해 기본으로 추가되는 이름입니다.
집계 결과의 이름을 바꾸고 싶다면 아래와 같이 alias를 추가할 수 있습니다.
>>> User.objects.aggregate(count=Count('id'))
{"count": 3}
Python
복사
SELECT COUNT(id) AS count FROM User
SQL
복사
count()
테이블의 레코드를 세는 기능은 자주 필요하기 때문에 Django는 이를 위한 count() 메소드를 지원합니다.
>>> User.objects.count()
3
Python
복사
SELECT COUNT(*) FROM User
SQL
복사
역시 결과는 하나로 집약됩니다.
NULL ≠ 0
한 가지 주의할 점이 있습니다.
aggregate()를 이용했을 때와 count()를 이용했을 때 생성되는 SQL이 다릅니다.
SQL COUNT() 함수에 컬럼명을 인자로 전달하면, 해당 컬럼을 기준으로 레코드 개수를 셉니다.
특정 컬럼 대신 *를 인자로 전달하면 모든 레코드의 개수를 셉니다.
그런데 특정 컬럼을 기준으로 집계할 때, 해당 컬럼이 NULL 값을 갖는 레코드는 집계에서 제외됩니다.
따라서 COUNT(”title”)의 경우, title 값이 NULL인 레코드는 제외하고 레코드 개수를 셉니다.
이는 다른 집계함수에서도 마찬가지입니다.
예를 들어, 상품 테이블이 있다고 하겠습니다.
상품 테이블에는 상품명 컬럼과 가격 컬럼이 있는데, 가격이 책정되지 않은 레코드가 존재합니다.
가격이 책정되지 않은 레코드는 가격을 NULL이라고 합시다.
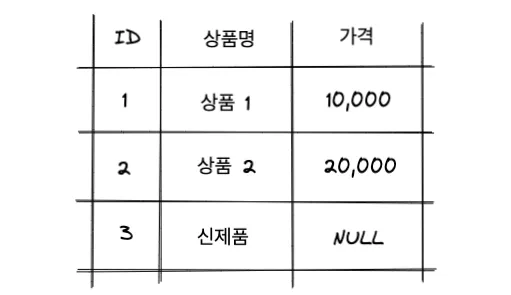
위 테이블에서 모든 상품의 가격 평균을 계산해봅시다.
>>> from django.db.models import Avg
>>> Goods.object.aggregate(Avg('price'))
{'prive__avg': 15000}
Python
복사
SELECT AVG(price) FROM Goods
SQL
복사
위 테이블에서 상품의 평균 가격은 15,000입니다.
상품의 레코드는 세 개가 존재하지만, 가격이 NULL인 마지막 레코드는 평균 집계에서 제외됩니다.
만약 신제품의 가격을 0으로 저장하면 어떻게 될까요?
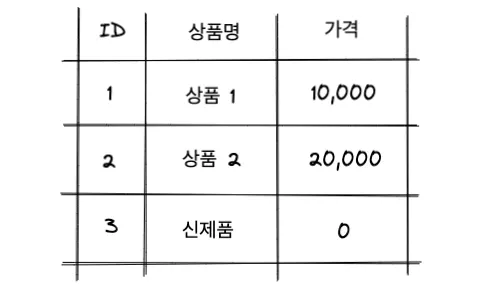
결과가 아래와 같이 달라집니다.
>>> Goods.object.aggregate(Avg('price'))
{'prive__avg': 10000}
Python
복사
이렇게 다른 결과가 나오는 이유는 NULL은 0이 아니기 때문입니다.
데이터베이스에서 NULL은 데이터가 없다는 것을 의미합니다.
다시 한 번 강조합니다. NULL은 0이 아닙니다.
집계 함수에 컬럼을 인자로 전달했을 때 해당 컬럼이 NULL인 레코드는 집계에서 제외된다는 것을 기억합시다.
BETWEEN
gt, gte, lt, lte
데이터를 조회할 때 날짜를 기준으로 조회하는 경우가 굉장히 많습니다.
User 테이블에서 가입일이 2022년인 회원을 조회해보겠습니다.
from datetime import date
# joined_at = models.DateField()
User.objects.filter(
joined_at__gte=date(2022, 1, 1), joined_at__lte=date(2022, 12, 31)
)
Python
복사
SELECT
*
FROM
User
WHERE
joined_at >= '2022-01-01' AND joined_at <= '2022-12-31'
SQL
복사
gt, gte, lt, lte는 비교 표현식으로 대체됩니다.
range()
Django는 특정 기간에 대해서 조회할 수 있도록 range() 메소드를 제공합니다.
range()를 이용하면 위의 ORM을 아래와 같이 바꿀 수 있습니다.
User.objects.filter(joined_at__range=(date(2022, 1, 1), date(2022, 12, 31)))
Python
복사
SELECT
*
FROM
User
WHERE
joined_at BETWEEN '2022-01-01' AND '2022-12-31'
SQL
복사
range()를 사용할 때 흔히 발생하는 실수는 조회 조건이 되는 마지막 날짜를 잘못 지정하는 것입니다.
range() 메소드는 BETWEEN문을 생성하는데, BETWEEN은 구간에 대해 inclusive하게 동작합니다.
inclusive하다는 말은 조건의 시작 값과 끝 값이 결과 집합에 포함된다는 말입니다.
2022년에 가입한 회원을 조회하기 위해 조건을 아래와 같이 지정한다면, 잘못된 결과가 나오게 됩니다.
SELECT
*
FROM
User
WHERE
joined_at BETWEEN '2022-01-01' AND '2023-01-01'
SQL
복사
BETWEEN문에 지정한 끝 값인 2023년 1월 1일에 가입한 회원이 결과 집합에 포함됩니다.
DateTimeField
또 다른 문제는 조회하는 joined_at 컬럼이 DateTimeField인 경우 입니다.
다시 22년 12월 31일까지 inclusive한 조건을 지정했다고 합시다.
from datetime import date
# joined_at = models.DateTimeField()
User.objects.filter(joined_at__range=(
datetime.date(2022, 1, 1), datetime.date(2022, 12, 31))
)
Python
복사
SELECT
*
FROM
User
WHERE
joined_at >= '2022-01-01 00:00:00' AND joined_at <= '2022-12-31 00:00:00'
SQL
복사
조회하는 컬럼이 datetime인 경우, 인자로 date를 전달했지만 쿼리는 datetime 포맷으로 생성됩니다.
Django가 컬럼에 맞게 시/분/초가 0인 datetime으로 변경한 것입니다.
따라서 위의 쿼리의 결과는 22년 12월 31일 0시 0분 0초에 가입한 회원의 결과까지만 포함합니다.
인자를 datetime으로 전달한 경우도, 시/분/초를 지정하지 않으면 위와 동일한 쿼리가 생성됩니다.
from datetime import datetime
# joined_at = models.DateTimeField()
User.objects.filter(joined_at__range=(
datetime(2022, 1, 1), datetime(2022, 12, 31))
)
Python
복사
SELECT
*
FROM
User
WHERE
joined_at >= '2022-01-01 00:00:00' AND joined_at <= '2022-12-31 00:00:00'
SQL
복사
따라서 end 조건에 대해 비교 표현식을 통해 exclusive하게 쿼리하는 것이 실수를 줄여줍니다.
from datetime import date
# joined_at = models.DateTimeField()
User.objects.filter(
joined_at__gte=date(2022, 1, 1), joined_at__lt=date(2023, 1, 1)
)
Python
복사
SELECT
*
FROM
User
WHERE
joined_at >= '2022-01-01 00:00:00' AND joined_at < '2023-01-01 00:00:00'
SQL
복사
UNION
union() 메소드를 이용하면 쿼리셋의 결과를 합칠 수가 있습니다.
일반 책과 전자책의 데이터가 아래와 같이 다른 테이블에 저장되어 있다고 합시다.
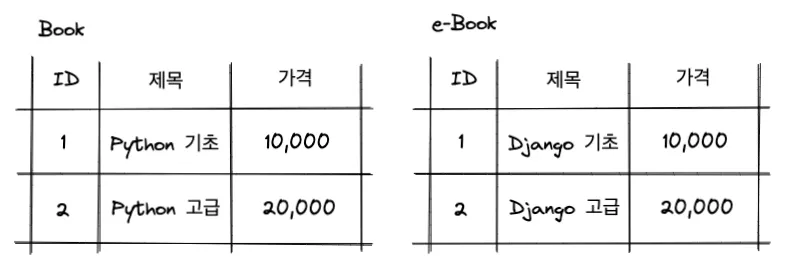
모든 책의 데이터를 아래와 같이 한 번에 조회할 때, union()을 사용하면 됩니다.
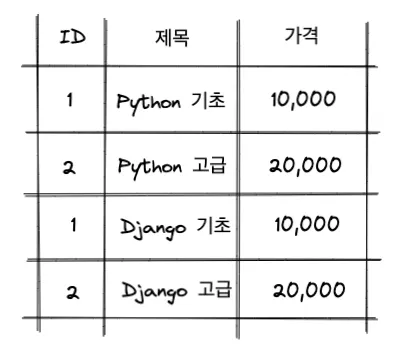
books = Book.objects.all()
ebooks = EBook.objects.all()
books.union(ebooks)
Python
복사
(SELECT * FROM Book) UNION (SELECT * FROM EBook)
SQL
복사
만약 두 테이블에서 책 제목을 나타내는 컬럼명이 다르다고 해보겠습니다.
컬럼명이 각각 Book 테이블에는 title이고, EBook 테이블에는 name이라고 합시다.
두 쿼리셋의 컬럼명이 달라도 결과 집합의 컬럼 개수가 같으면 union()을 수행할 수 있습니다.
books = Book.objects.values_list('id', 'title', 'price')
ebooks = EBook.objects.values_list('id', 'name', 'price')
books.union(ebooks)
Python
복사
(
SELECT
id,
title,
price
FROM
Book) UNION (
SELECT
id,
name,
price
FROM
EBook)
SQL
복사
SQL UNION 문은 각 레코드가 유니크한지 검사합니다.
따라서 union()을 사용할 때 레코드의 유니크 검사가 꼭 필요한게 아니라면 all=True 옵션을 사용합시다.
books.union(ebooks, all=True)
Python
복사
(SELECT id, title, price FROM Book)
UNION ALL
(SELECT id, name, price FROM EBook)
SQL
복사
SELECT
annotate()
UNION 된 결과에 각 레코드가 일반 책인지 전자 책인지를 추가로 출력한다고 합시다.
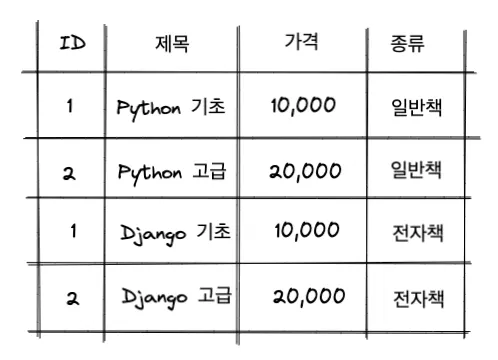
다음과 같이 annotate()를 이용하면 출력 결과에 컬럼을 추가할 수 있습니다.
from django.db.models import Value
books = Book.objects.annotate(book_type=Value('일반책'))
ebooks = EBook.objects.annotate(book_type=Value('전자책'))
books.union(ebooks, all=True)
Python
복사
(SELECT id, title, price, '일반책' AS book_type FROM Book)
UNION ALL
(SELECT id, name, price, '전자책' AS book_type FROM EBook)
SQL
복사
위 예시는 Value() 오브젝트로 값을 출력했지만, F() 오브젝트를 이용하면 컬럼 간의 연산도 가능합니다.
예를 들어, 책 테이블에 가격과 할인 금액 컬럼이 있고, 판매 가격 = 가격 - 할인 금액 이라고 합시다.
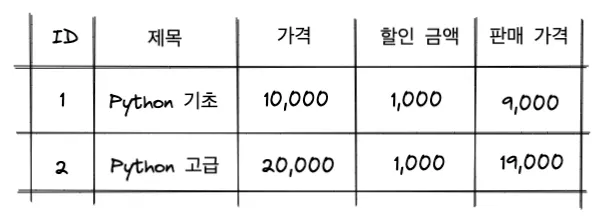
다음과 같이 F() 오브젝트를 이용하면 컬럼 간 연산 결과를 새로운 컬럼으로 출력할 수 있습니다.
from django.db.models import F
Book.objects.annotate(sale_price=F('price') - F('discount'))
Python
복사
SELECT
id,
title,
price,
discount,
price - discount AS sale_price
FROM
Book
SQL
복사
union()이 수직으로 레코드를 확장 시킨다면, annotate()는 수평으로 컬럼을 확장 시킵니다.
values() vs. only()
특정 컬럼의 결과만 출력하고 싶은 경우 values() 또는 values_list()를 사용할 수 있습니다.
>>> User.objects.values('id', 'name')
<QuerySet [{'id': 1, 'name': 'Guido'}]>
>>> User.objects.values_list('id', 'name')
<QuerySet [(1, 'Guido')]>
Python
복사
SELECT id, name FROM User
SQL
복사
두 메소드는 동일한 SQL을 수행하지만 반환하는 데이터 타입이 다릅니다.
QuerySet 안에 values()는 Dict를 반환하고, values_list()는 Tuple을 반환합니다.
두 메소드가 반환하는 데이터 타입은 모두 QuerySet이지만 내부 아이템이 instance가 아닙니다.
따라서 values()와 values_list()를 이용한 경우, 반환된 쿼리셋을 기존처럼 사용할 수 없습니다.
예를 들어, 기존 쿼리셋은 instance를 통해 ForeignKey로 연결된 객체에 접근할 수 있습니다.
>>> user = User.objects.first()
>>> user.profile
<UserProfile: Guido's profile>
Python
복사
하지만 values()는 Dict를 반환하기 때문에 아래와 같이 ForeignKey의 id만 확인할 수 있습니다.
>>> User.objects.values('profile').first()
{'profile': 1}
Python
복사
또 values()와 values_list()의 경우, instance의 property에 접근할 수 없습니다.
@property
def is_active(self):
return bool(not self.unregistered_at) # 탈퇴일 없으면 활성 유저
Python
복사
>>> users = User.objects.all()
>>> active_users = [user for user in users if user.is_active]
Python
복사
N+1 쿼리 문제를 방지하기 위해 Django는 select_related()와 prefetch_related()를 제공합니다.
하지만 values()를 사용하면 select_related()와 prefetch_related()가 무시됩니다.
>>> User.objects.select_related('profile')
Python
복사
SELECT * FROM User U
LEFT OUTER JOIN Profile P
ON U.id = P.user_id
SQL
복사
>>> User.objects.select_related('profile').values()
Python
복사
SELECT * FROM User
SQL
복사
따라서 기존 쿼리셋처럼 사용하면서 SELECT 문에 특정 컬럼만 출력하고 싶은 경우 only()를 사용합시다.
>>> User.objects.only('name')
Python
복사
SELECT id, name FROM User # id는 항상 포함
SQL
복사
values() ≠ GROUP BY
간혹 values()를 GROUP BY라고 생각하는 경우가 있습니다. 절반만 맞는 말입니다.
GROUP BY는 레코드의 집계를 위해 사용되는 구문이지만, values()는 개별 레코드에 대한 메소드입니다.
앞서 언급했듯이 모든 ORM 메소드가 SQL 구문과 일대일로 대응되는 것은 아닙니다.
values() 메소드의 기능은 특정 컬럼을 기준으로 한 Dict로 쿼리셋을 생성하는 것입니다.
대신 values() 메소드는 특정한 방법으로 사용했을 때 GROUP BY처럼 동작합니다.
자세한 내용은 조금 뒤에 설명하겠습니다.
alias
annotate()로 지정해준 컬럼은 SELECT 문에 기존 컬럼보다 늦게 선언됩니다.
Book.objects.annotate(sale_price=F('price') - F('discount'))
Python
복사
SELECT
id,
title,
price,
discount,
price - discount AS sale_price
FROM
Book
SQL
복사
할인 가격(sale_price)을 annotate 한 경우, SELECT 문에 기존 컬럼들이 먼저 선언된 이후 추가됩니다.
일반적으로 SELECT 문에 선언하는 컬럼의 순서는 크게 중요하지 않습니다.
하지만 SELECT 문에 선언되는 컬럼의 순서를 바꾸어야 한다면 다음과 같은 방법을 이용할 수 있습니다.
아쉽게도 이 방법은 values()에만 사용할 수 있습니다.
annotate() 메소드에 컬럼 이름을 지정한 것처럼, values()에도 컬럼 이름을 지정할 수 있습니다.
queryset = (
Book.objects
.annotate(sale_price=F('price') - F('discount'))
.values(
_sale_price=F('sale_price'),
_price=F('price'),
_discount=F('discount'),
)
)
SQL
복사
SELECT
price - discount AS _sale_price,
price AS _price,
discount AS _discount
FROM Book
SQL
복사
values()에 컬럼 이름을 지정하면, SELECT 문에 alias를 추가하여 지정한 순서대로 쿼리합니다.
alias에 _를 추가한 이유는 원본 컬럼 이름을 그대로 alias로 사용할 수 없기 때문입니다.
GROUP BY
values() & annotate()
집계함수를 사용하기 위해서 aggregate() 메소드를 사용하는 방법을 소개했습니다.
aggregate()는 항상 결과를 하나로 집약합니다.
이는 테이블에 포함된 모든 레코드를 구분하지 않고 집계하기 때문입니다.
그런데 GROUP BY를 이용하면, 테이블을 조건 별로 여러 집합으로 나누어 집계할 수 있습니다.
예를 들어, 성별에 따른 유저수 집계를 알고 싶다면 GROUP BY gender처럼 집합을 구분할 컬럼을 지정합니다.
Django ORM에서는 values()와 annotate()를 함께 사용하면 됩니다.
values()에는 집합을 구분할 컬럼을 지정하고, annotate()에는 집계함수를 지정합니다.
>>> User.objects.values('gender').annotate(count=Count('id'))
<QuerySet [{'gender': 'M', 'count': 2}, {'gender': 'F', 'count': 1}]>
Python
복사
SELECT gender, COUNT(id) AS count FROM User GROUP BY gender
SQL
복사
앞서 설명했듯이 values()는 레코드에서 출력할 컬럼을 지정하는 메소드입니다.
추가로 annotate()에 집계함수가 선언되었기 때문에 values()에 지정한 컬럼 별로 집계되는 것입니다.
위의 예시에서 annotate() 없이 values()만 있는 경우, 각 레코드 별로 gender를 출력합니다.
>>> User.objects.values('gender')
<QuerySet [{'gender': 'M'}, {'gender': 'M'}, {'gender': 'F'}]>
SQL
복사
따라서 values()가 GROUP BY라고 생각하는 것은 옳지 않습니다.
values()와 집계함수를 포함한 annoate()가 함께 사용되었을 때 GROUP BY로 동작합니다.
GROUP BY로 동작하기 위해서는 values()와 annotate()의 순서가 중요합니다.
>>> User.objects.annotate(count=Count('id')).values('gender')
<QuerySet [{'gender': 'M'}, {'gender': 'M'}, {'gender': 'F'}]>
Python
복사
annotate() 뒤에 values()가 오면, 어떤 컬럼이 annotate 되었든 values()에 있는 컬럼만 출력됩니다.
다중 컬럼 GROUP BY
GROUP BY로 집계하는 경우, SELECT 문에는 GROUP BY에 선언된 컬럼과 집계함수만 올 수 있습니다.
예를 들어, 다음과 같은 SQL은 에러를 일으킵니다.
SELECT
id, # 에러
gender,
COUNT('gender')
FROM
User
GROUP BY
gender
SQL
복사
위의 SQL이 에러를 일으키는 이유는 gender 별로 분류한 집합에서 하나의 id를 특정할 수 없기 때문입니다.
따라서 values()에 여러개의 컬럼이 포함된 경우, 해당 컬럼들은 모두 GROUP BY와 SELECT에 사용됩니다.
>>> User.objects.values('gender', 'age').annotate(count=Count('id'))
Python
복사
SELECT
gender,
age,
COUNT(id) AS count,
FROM
User
GROUP BY
gender,
age
SQL
복사
만약 각 성별의 대표되는 id를 출력하고 싶다면, 집계함수를 이용하도록 다음과 같이 바꾸어야합니다.
>>> (User.objects.values('gender', 'age')
... .annotate(count=Count('id'), representative_id=Min('id')))
Python
복사
SELECT
MIN(id) AS representative_id,
gender,
age,
COUNT(id) AS count,
FROM
User
GROUP BY
gender,
age
SQL
복사
이어지는 심화편에서 index를 효율적으로 이용할 수 있는 방법 등 실전에 필요한 ORM 사용법을 알아보겠습니다.

